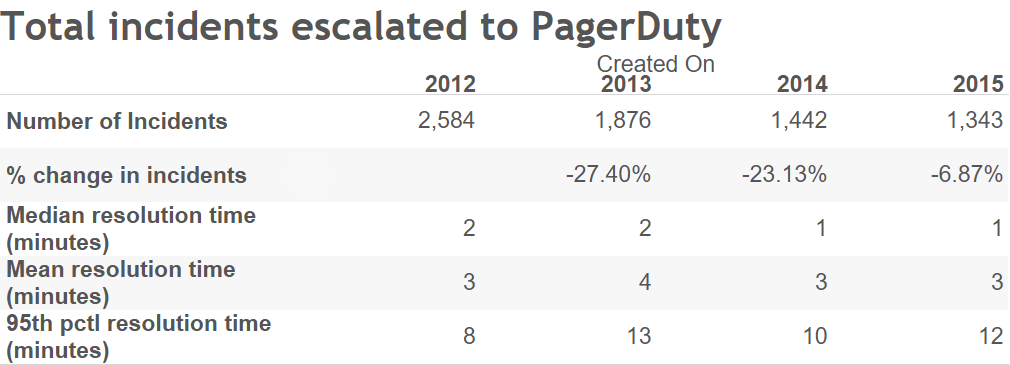
tldr; The bottom line is that we had fewer actual site down interruptions and false alarm escalations in 2015.
Here’s a non exhaustive list of contributing factors to these improvements over the years:
- Eliminating scheduled maintenance that would take a site offline
- Limiting API abuse (and a general decrease in the number of abuse incidents)
- Automated blocking of other common abuse traffic
- Fairly generous ongoing hardware refresh with better distribution across cabinets
- Completely new core and top of rack network switches
- Hiring the right people (and the right number of people)
- Moving to more stable storage (EMC / Isilon to Cleversafe)
- Taking control of our public Internet connectivity and routing (Our own IP space, our own routers, carefully selected providers, filtering traffic)
- Right sizing database hardware for every major application
- Better development / deployment practices and consistency in following those practices (local tests / ci, staging, rollout, production)
- Practicing incident response and keeping play books up to date
- Vastly improved metrics and dashboards
- Better application architecture and design choices with regard to availability and failure modes
- Being ruthless in our tuning of internal monitoring and alerting (Nagios) to only escalate alerts that really need to be escalated
- (Full disclosure we actually had more incidents escalated from our internal monitoring this year. The “quality” of those escalations is higher though.)